Voice of the Customer (VoC) analytics platform built as a proof of concept demonstrating how LLMs can extract structured business intelligence from insurance call centre transcripts at scale. The pipeline processes real PII-redacted call transcripts, analyses them through a carefully engineered Gemini 2.5 Flash extraction prompt, stores structured insights in ArangoDB, and serves a live dashboard through an N8N webhook — all with zero external hosting dependencies.
The Challenge
Insurance call centres generate thousands of hours of customer conversations daily. Buried within these calls are critical business signals: frustrated customers about to churn, recurring billing complaints, agents who need coaching support, and policy issues that drive repeated contact. Manual review doesn't scale, and traditional keyword-based analytics miss the nuance of human conversation — sarcasm, subtle frustration, sentiment shifts during a call, and context-dependent meaning.
Architecture & Technical Design
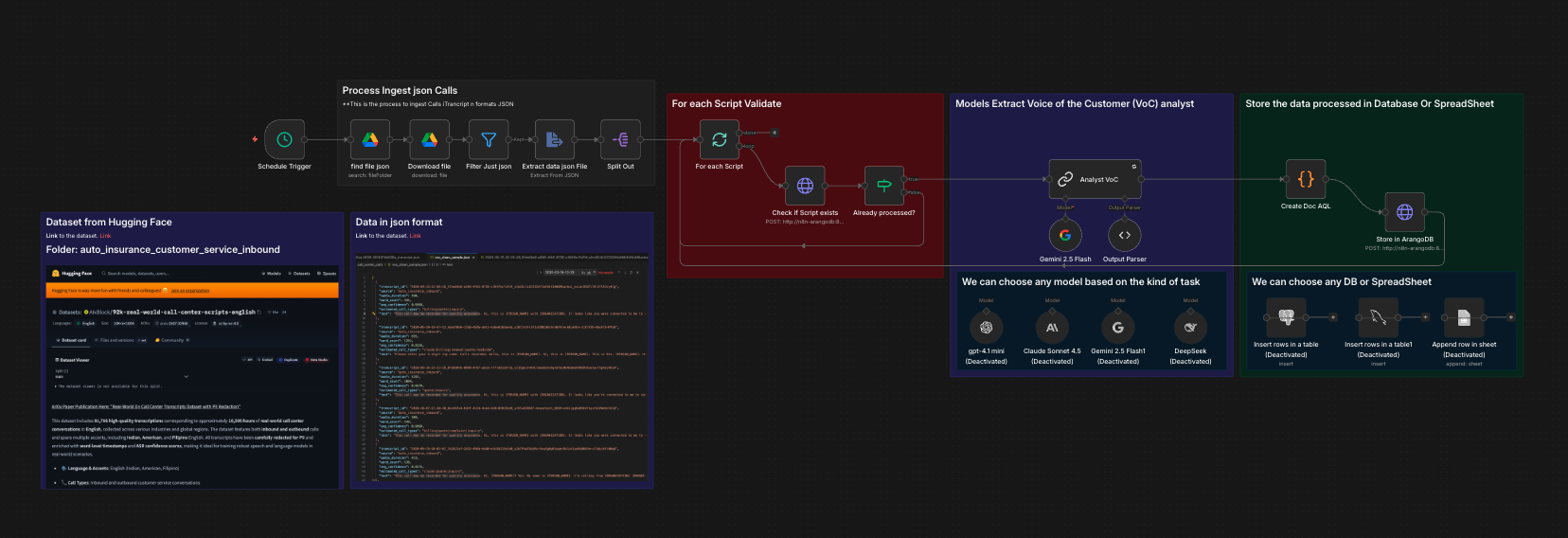
The pipeline runs as a sequence of N8N workflow stages:
- Data Ingestion: JSON transcript files loaded from Google Drive, filtered for quality, split into individual records
- Deduplication: Each transcript checked against ArangoDB before LLM processing — prevents redundant API calls and cost waste
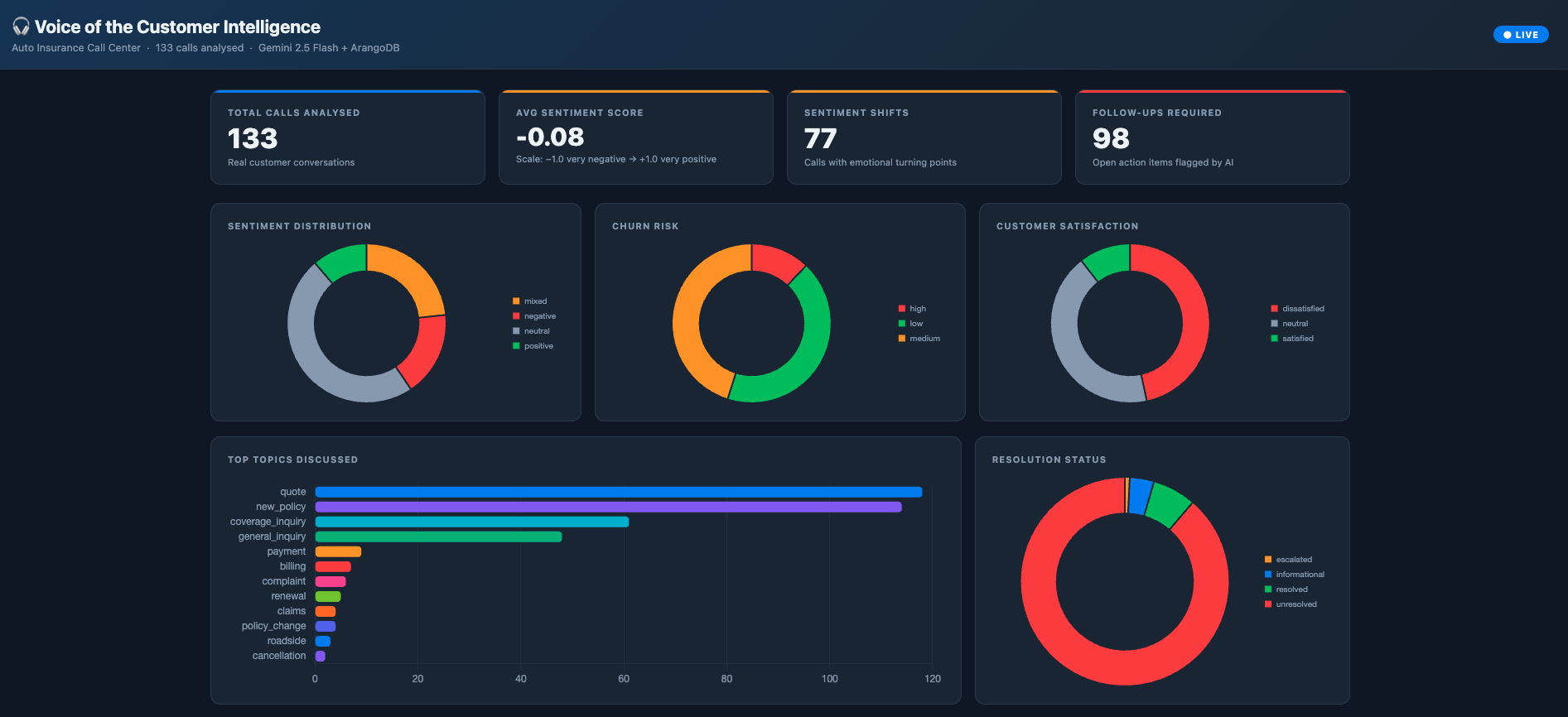
- LLM Extraction: Gemini 2.5 Flash analyses each transcript with a structured extraction prompt returning 16 fields:
- Sentiment (positive/negative/neutral/mixed) with calibrated score (-1.0 to +1.0)
- Sentiment journey — narrative arc of how customer mood evolved during the call
- Sentiment shifts detection (boolean + description)
- Topic classification against fixed taxonomy (claims, billing, policy_change, complaint, renewal, quote, roadside, cancellation, coverage_inquiry, payment, new_policy, general_inquiry)
- Key issues in plain language (case-note quality, not generic labels)
- Resolution status, customer satisfaction, urgency, call type
- Agent performance assessment
- Churn risk prediction (low/medium/high)
- Follow-up required flag
- Validation & Enrichment: Code node unwraps LLM output, merges with original metadata (audio duration, ASR confidence, source), generates ArangoDB document key
- Storage: AQL UPSERT into ArangoDB collection via cursor API — prevents duplicates on reprocessing
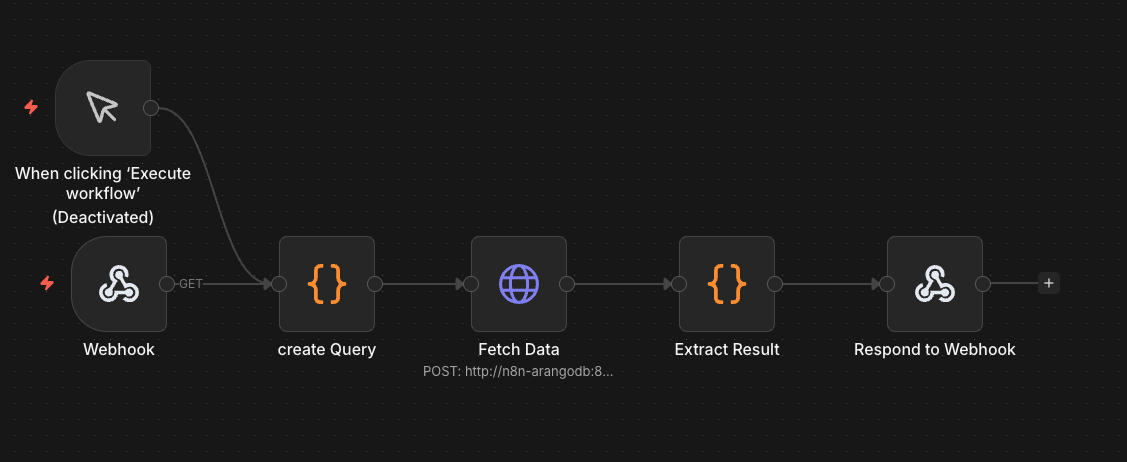
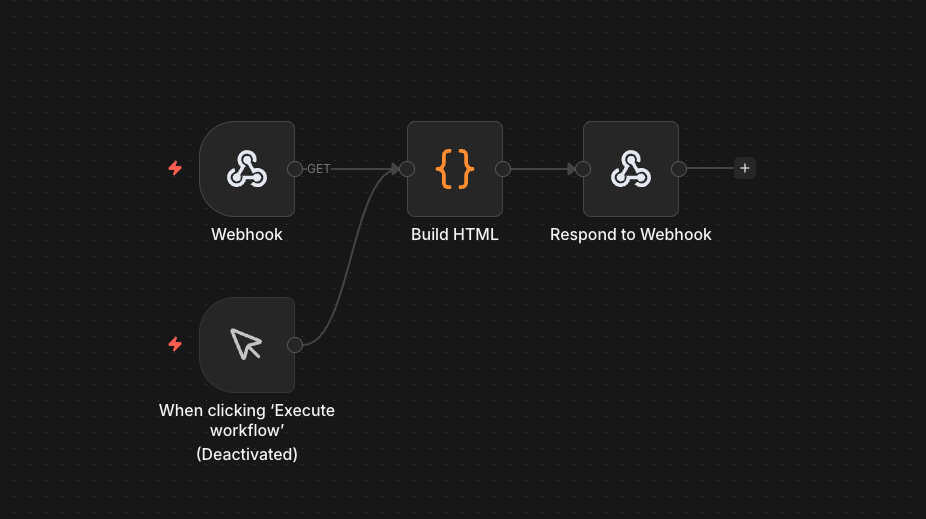
- Dashboard: Separate webhook workflow queries ArangoDB with server-side AQL aggregation, builds HTML with Chart.js, returns complete page via Respond to Webhook node
Key Technical Decisions
- Model Selection: Benchmarked GPT-4.1 Mini vs Gemini 2.5 Flash on identical transcripts. GPT-4.1 Mini consistently flattened subtle frustration to "neutral" (sentiment_score: 0, sentiment_shifts: false). Gemini 2.5 Flash correctly detected sentiment shifts — for example, identifying a customer who said "I don't want to waste my time" as negative (-0.5) with sentiment_shifts: true and a detailed sentiment journey. Selected Flash for production use.
- Prompt Engineering: The extraction prompt includes calibrated sentiment scoring with explicit examples at each level (-1.0 to +1.0), rules for detecting even subtle sentiment shifts, good/bad examples for key_issues to prevent generic labels, churn risk assessment criteria, edge case handling for IVR recordings and cut-off transcripts, and PII placeholder handling.
- Deterministic Code Nodes: All scoring, aggregation, and data transformation handled by JavaScript Code nodes — LLM only does extraction. Same philosophy used in production recruitment matching system.
- Dashboard Architecture: Webhook-served HTML with server-side AQL aggregation — the query runs inside ArangoDB (grouping, counting, sorting) and returns a single pre-aggregated object. No external hosting, no frontend framework, no CORS issues.
Dataset
Processed the CallCenterEN dataset from Hugging Face — 92,000+ real-world PII-redacted call centre transcripts. Filtered and curated 500 high-quality insurance conversations from auto_insurance_customer_service_inbound, insurance_outbound, automotive_and_healthcare_insurance_inbound, and customer_service_general_inbound sources.
- Average transcript: 10.6 minutes
- Average word count: 1,166 words
- Average ASR confidence: 0.94
Results
- 16-field structured extraction per transcript with consistent schema compliance
- Calibrated sentiment detection catching nuanced frustration that competing models missed
- Deduplication preventing redundant LLM processing on rerun
- Live dashboard served from webhook with real-time ArangoDB aggregation
- Full pipeline built from concept to working demo in days