Built for a leading Australian mortgage broker company, this system solves a critical operational problem: brokers spend excessive time manually searching through checklists, bank-specific guides, templates, settlement procedures, and forms to answer time-sensitive client questions. The Enterprise RAG Document Chatbot replaces that manual process with an AI-powered natural language interface that retrieves source-attributed answers from the correct document — with full traceability and no AI fabrication.
Problem Statement
- Operational Bottleneck: Brokers manually searching a large, growing document library for time-critical information during client calls and settlements
- Accuracy Risk: Outdated documents or incorrect manual lookups introduced compliance and settlement risk
- No Source Attribution: Standard keyword search returned lists of documents — not answers — requiring brokers to read and interpret content themselves
- Hallucination Risk: Generic AI tools fabricated procedural details, unacceptable in a regulated financial services environment
- Scale: Document library spans PDF, DOCX, XLSX, CSV, and image formats with continuous updates from lenders
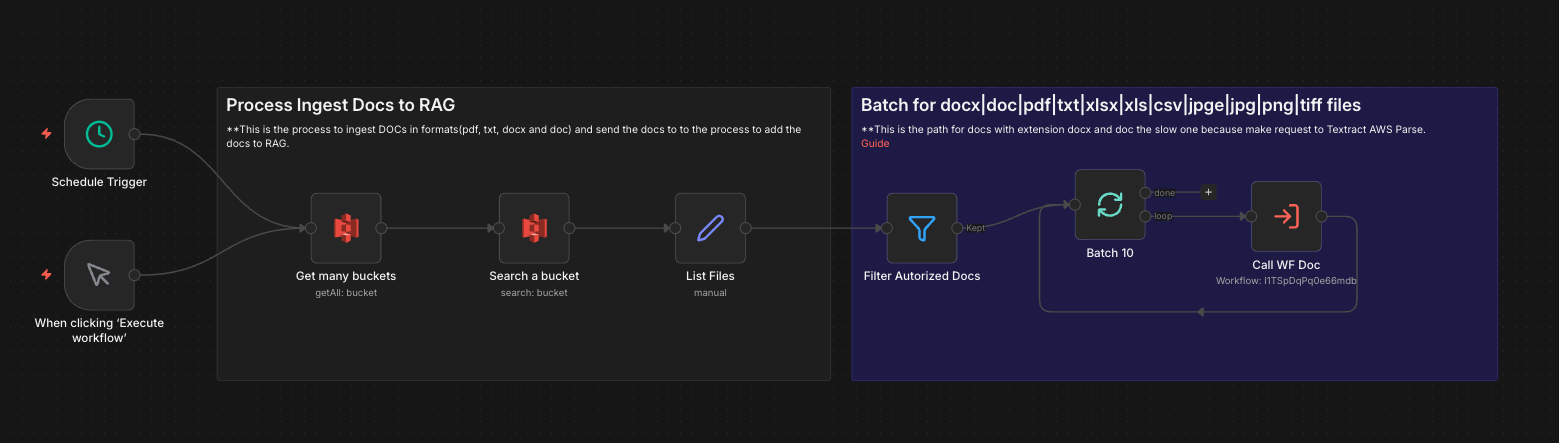
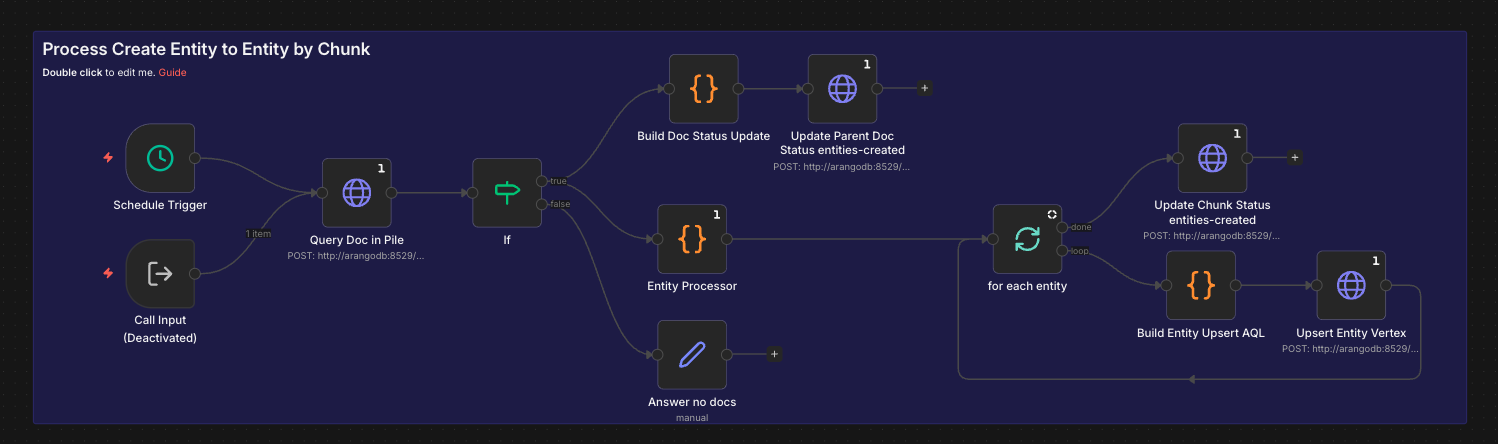
Document Ingestion Pipeline
- Source: Documents stored in AWS S3 across multiple lender-specific folders
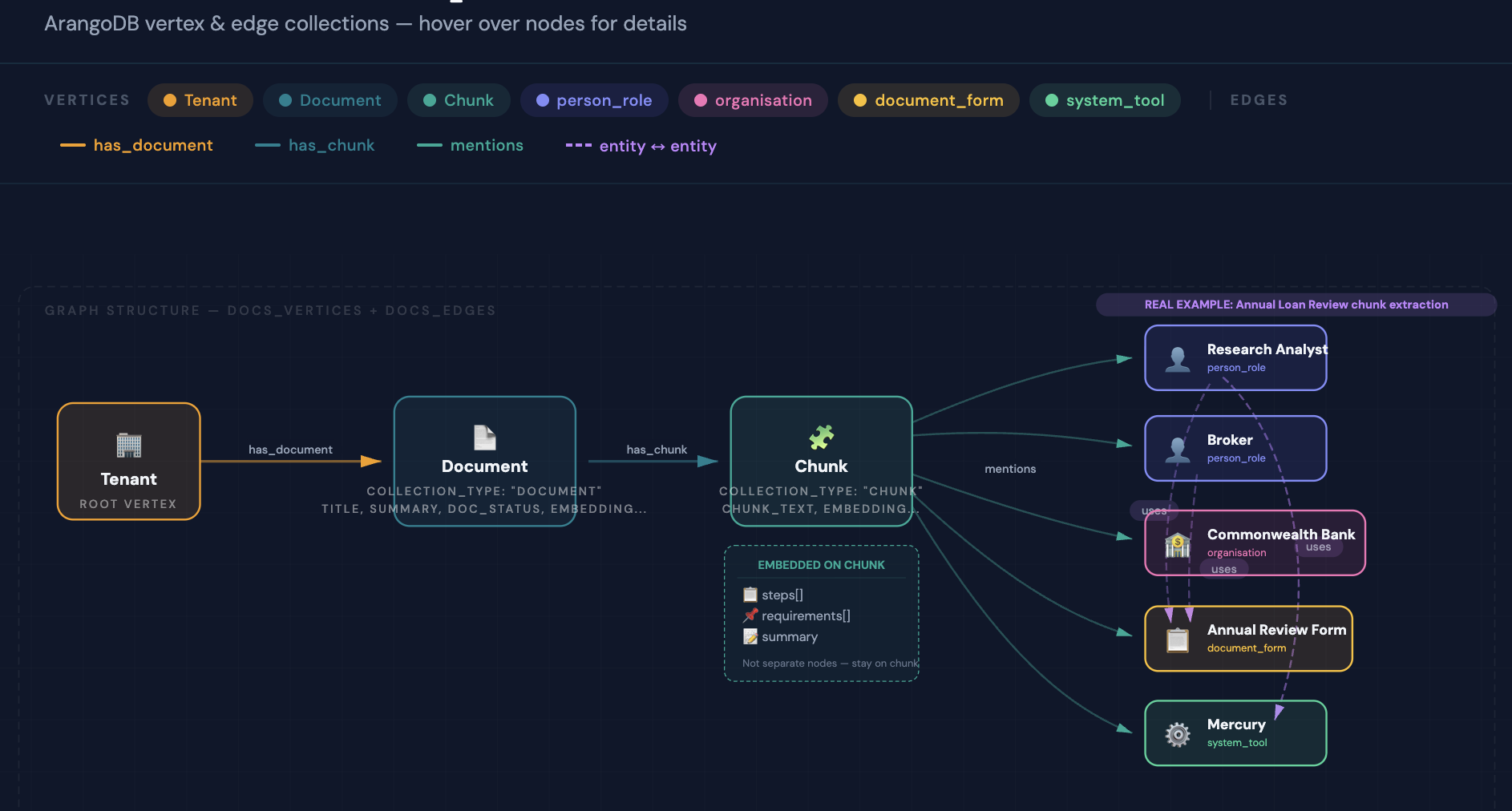
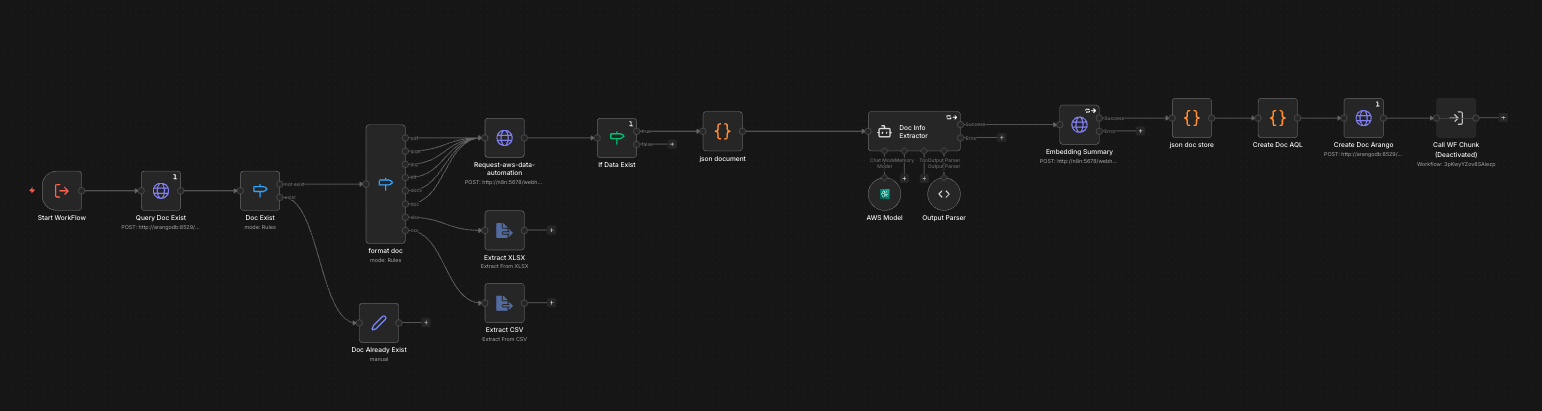
- Extraction: AWS Bedrock Data Automation (BDA) processes PDF, DOCX, XLSX, CSV, and image files into structured markdown
- Semantic Chunking: N8N workflow splits documents into semantically coherent chunks (not fixed token splits) to preserve context boundaries
- AI Enhancement: Claude Haiku enriches each chunk with contextual metadata — document type, lender, relevant process stage, and inferred intent
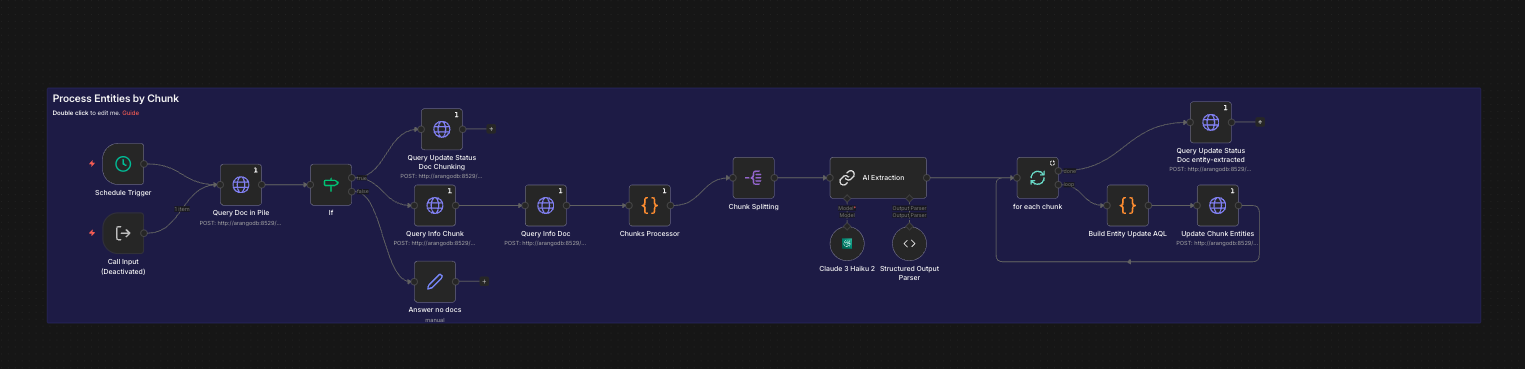
- Entity Extraction: Claude Haiku identifies named entities (lenders, forms, conditions, deadlines) and their relationships
- Graph Insertion: Documents, chunks, lenders, forms, and entities stored as ArangoDB vertices; relationships stored as directed edges enabling graph traversal queries
- Vector Embedding: AWS Titan Text Embeddings V2 generates vector representations for each chunk, stored alongside the graph for hybrid search
Query Pipeline
- Natural Language Query → Intent classification determines query type (procedural, document lookup, lender-specific, comparison)
- Hybrid Retrieval: Vector similarity search (Titan Embeddings) combined with AQL graph traversal — graph paths surface related entities keyword search cannot find
- Confidence Scoring: Each retrieved chunk assigned a confidence score based on vector similarity, graph path depth, and entity match count
- Context Assembly: Top-ranked chunks assembled into a grounded context window with source attribution metadata
- Verbatim Generation: Claude Haiku generates responses anchored strictly to retrieved content — no inference beyond source material
- Source Attribution: Every response includes document name, section, and lender origin so brokers can verify and cite the source
State Manager — Document Lifecycle Control
A centralised N8N State Manager workflow governs the entire document lifecycle with atomic locking to prevent concurrent processing conflicts — critical when multiple document updates arrive simultaneously from different lenders:
- Detects new/updated/deleted documents via S3 event triggers
- Acquires an atomic lock on the document record before processing begins
- Coordinates the full pipeline: extract → chunk → enhance → embed → upsert graph
- Releases lock and updates document status on completion or failure
- Handles version conflicts — newer versions supersede older ones without manual intervention
Strategic Model Selection — 12x Cost Reduction
A deliberate model selection strategy reduced AI inference costs by 12x compared to using a single frontier model throughout:
- AWS Bedrock Data Automation: Handles document parsing (PDF, images) — purpose-built, no LLM cost per page
- Claude Haiku: Used for contextual enhancement, entity extraction, and response generation — high throughput, low cost, sufficient accuracy for structured tasks
- Titan Embeddings V2: Vector generation at AWS-native pricing, no third-party API calls
- Claude Sonnet reserved only for complex multi-document synthesis queries where higher reasoning is demonstrably needed